OpenGIN Architecture Overview
System Overview
OpenGIN is a data orchestration and networking framework. It is based on a polyglot database and a microservices-based design that handles entities with metadata, attributes, and relationships. The architecture follows a layered approach with REST/gRPC communication protocols.
High-Level Architecture Diagram
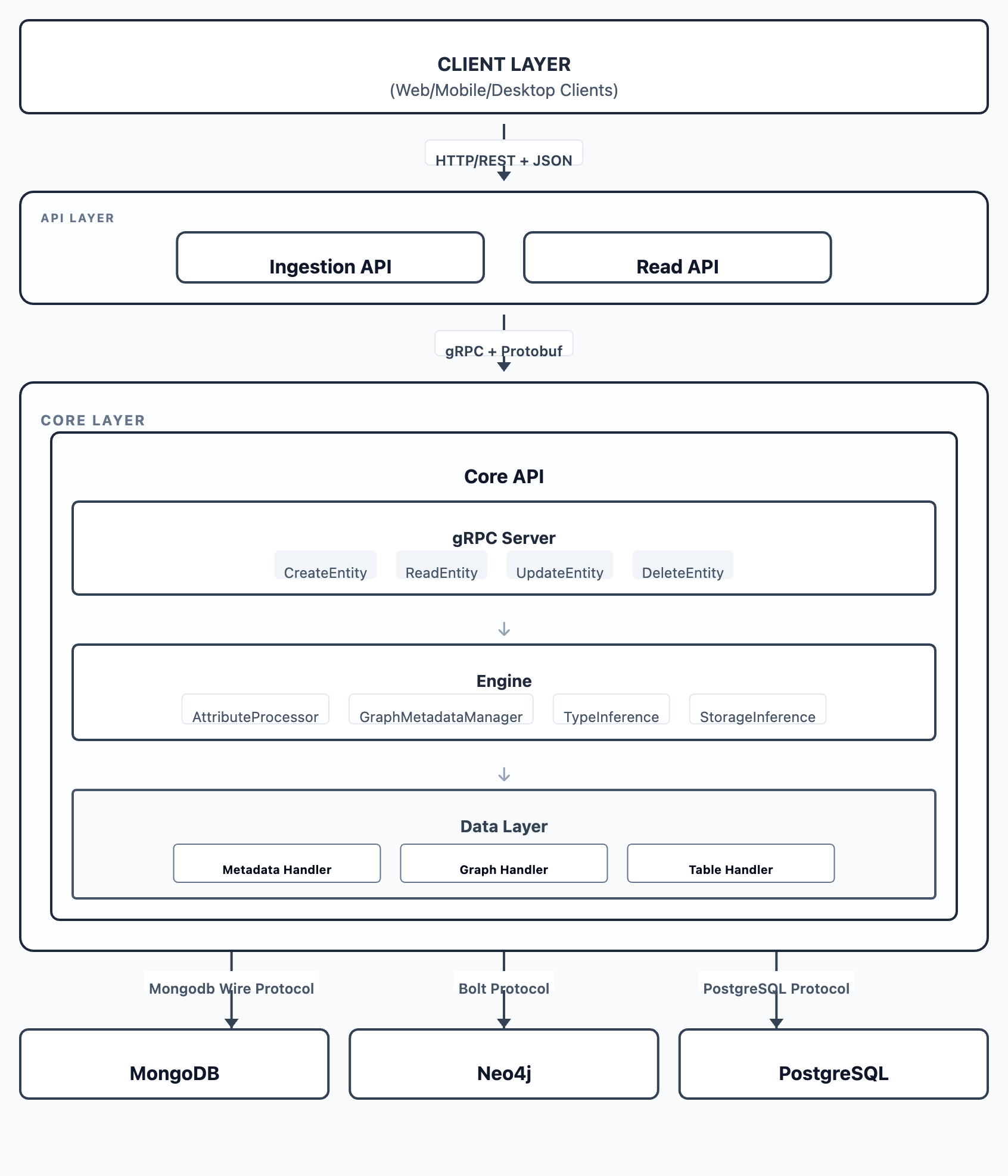
Architecture Layers
1. API Layer (Client-Facing Services)
Ingestion API
The Ingestion API is responsible for handling entity mutations, including creation, updates, and deletions. Implemented as a Ballerina REST service, it accepts JSON payloads from clients, validates their structure, and converts them into Protobuf Entity messages. It then communicates with the Core API via gRPC and handles the conversion of Protobuf responses back to JSON for the client.
Read API
The Read API manages entity queries and retrieval. Also built as a Ballerina REST service, it accepts read requests and supports selective field retrieval, filtering, and search capabilities. It interfaces with the Core API using gRPC to fetch data and returns formatted JSON responses to the client.
2. Service Layer
Core API
The Core API acts as the central orchestration service, managing data networking and interactions across the distributed database system. It exposes a gRPC server to handle entity operations such as creation, reading, updating, and deletion.
Internally, the service utilizes an Engine Layer to process attributes, manage graph metadata, and perform type and storage inference. The Repository Layer abstracts the interactions with underlying databases, coordinating metadata storage in MongoDB, graph management in Neo4j, and attribute storage in PostgreSQL.
3. Database Layer
MongoDB
MongoDB is used for flexible metadata storage. Its document-based, schema-less structure allows for efficient handling of the dynamic metadata associated with entities.
Neo4j
Neo4j serves as the specialized storage for entities and their relationships. By representing entities as nodes and relationships as directed edges, it optimizes the system for complex graph traversals and relationship-based queries.
PostgreSQL
PostgreSQL provides robust storage for time-based attributes. It ensures ACID compliance and supports complex queries, making it ideal for managing time-series data and the evolution of attribute schemas.
4. Supporting Services
Cleanup Service
The Cleanup Service is a utility designed for database maintenance and testing. It provides a mechanism to clear PostgreSQL tables, drop MongoDB collections, and remove Neo4j nodes and relationships, facilitating a clean state for development and testing environments.
Backup/Restore Service
The Backup and Restore Service ensures data persistence and version management. It handles the creation of local backups for all databases, stores them with versioning on GitHub, and supports automated restoration from specific backup releases.
Data Model
Entity Structure (Protobuf)
message Entity {
string id = 1; // Unique identifier
Kind kind = 2; // major/minor classification
string created = 3; // Creation timestamp (ISO 8601)
string terminated = 4; // Optional termination timestamp
TimeBasedValue name = 5; // Entity name with temporal tracking
map<string, google.protobuf.Any> metadata = 6; // Flexible metadata
map<string, TimeBasedValueList> attributes = 7; // Time-based attributes
map<string, Relationship> relationships = 8; // Entity relationships
}
message Kind {
string major = 1; // Primary classification
string minor = 2; // Secondary classification
}
message TimeBasedValue {
string startTime = 1; // Value valid from
string endTime = 2; // Value valid until (empty = current)
google.protobuf.Any value = 3; // Actual value (any type)
}
message Relationship {
string id = 1; // Relationship identifier
string relatedEntityId = 2; // Target entity
string name = 3; // Relationship type
string startTime = 4; // Relationship valid from
string endTime = 5; // Relationship valid until
string direction = 6; // Relationship direction
}
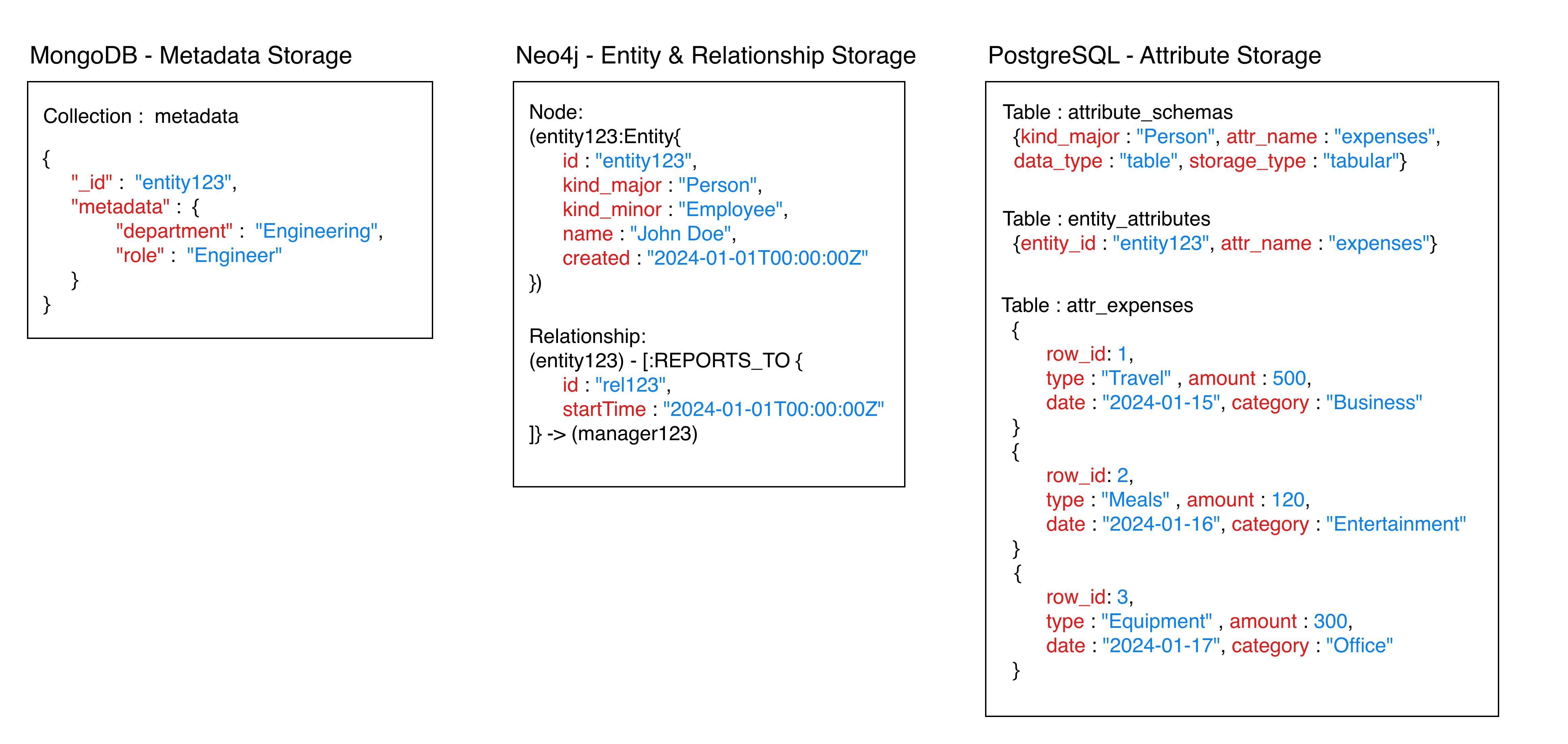
Storage Distribution Strategy
The entity data is strategically distributed across three databases:
Example Entity:
{
"id": "entity123",
"kind": {"major": "Person", "minor": "Employee"},
"name": "John Doe",
"created": "2024-01-01T00:00:00Z",
"metadata": {"department": "Engineering", "role": "Engineer"},
"attributes": {
"expenses": {
"columns": ["type", "amount", "date", "category"],
"rows": [
["Travel", 500, "2024-01-15", "Business"],
["Meals", 120, "2024-01-16", "Entertainment"],
["Equipment", 300, "2024-01-17", "Office"]
]
}
},
"relationships": {"reports_to": "manager123"}
}
Storage Distribution:
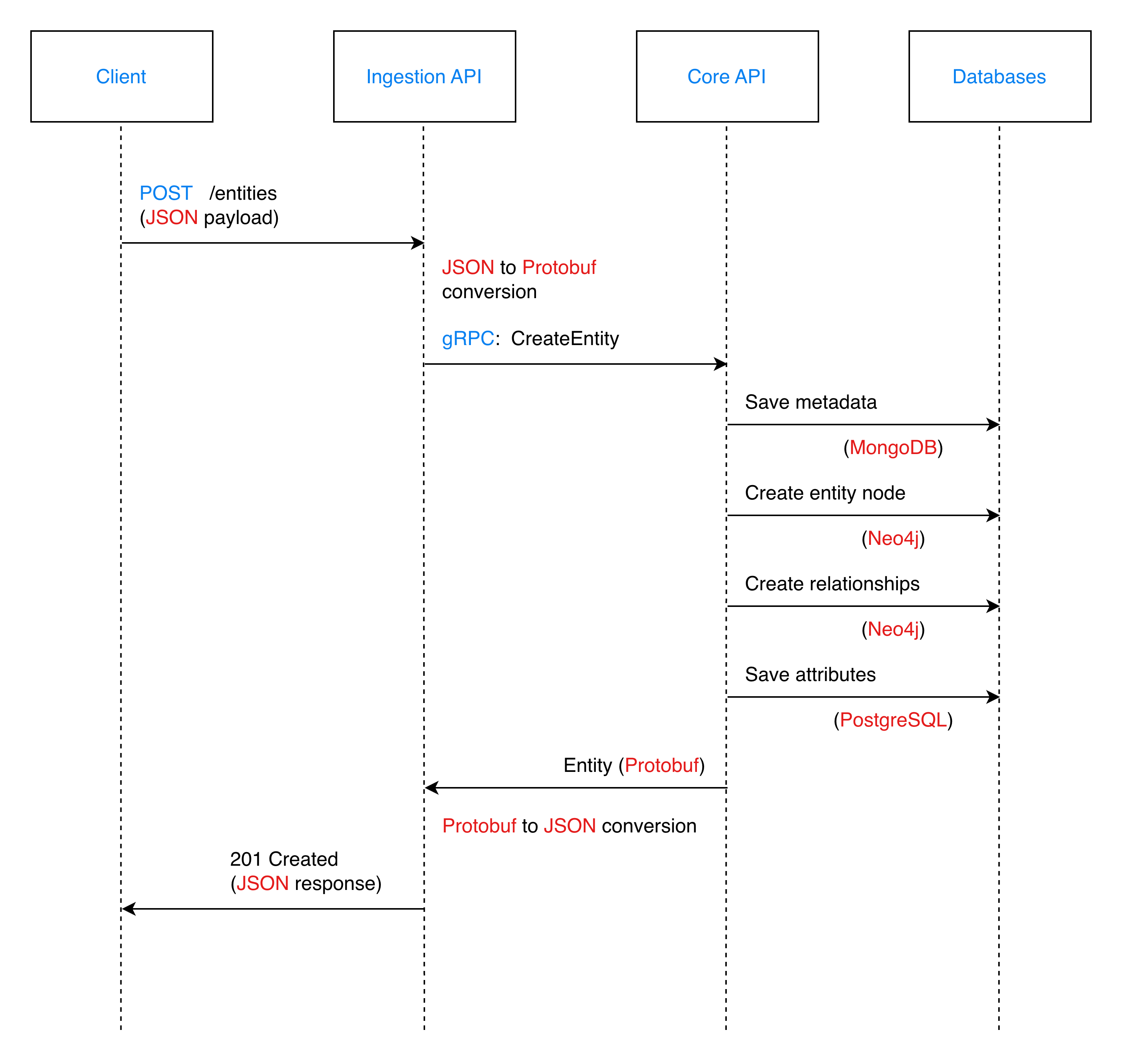
Data Flow Sequences
Create Entity Flow
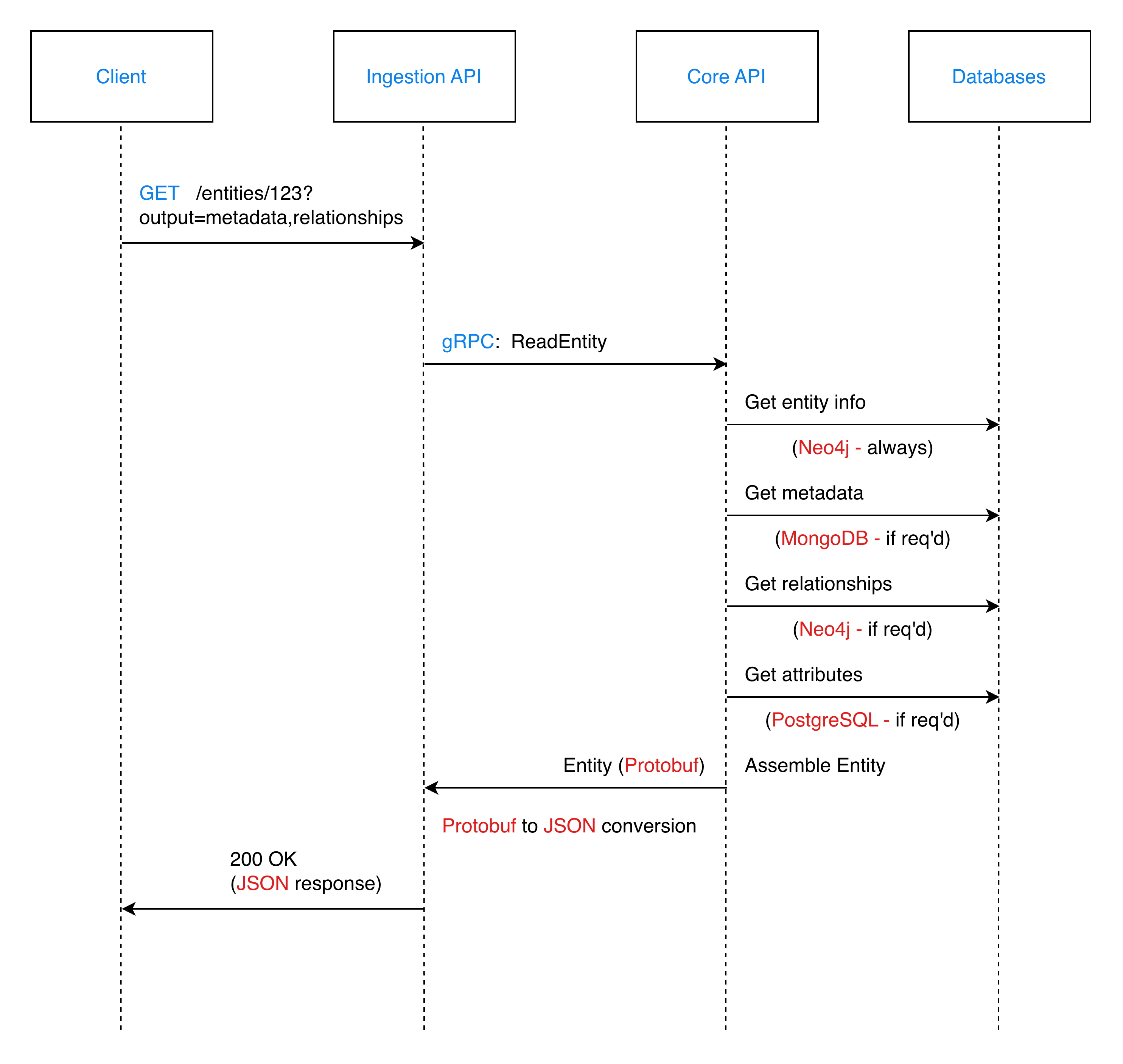
Read Entity Flow
Type System
Type Inference System
The Type Inference System automatically detects data types to eliminate the need for manual specification. It identifies primitive types such as integers, floats, strings, and booleans, as well as special temporal types like dates, times, and datetimes, assigning the appropriate type based on the input value's format.
Storage Type Inference
The Storage Type Inference mechanism determines the optimal storage structure for data. It categorizes input into formats such as tabular (for data with rows and columns), graph (for nodes and edges), list, scalar, or map, ensuring efficient storage and retrieval.
Communication Protocols
| Layer | Protocol | Format | Port |
|---|---|---|---|
| Client ↔ Ingestion API | HTTP/REST | JSON | 8080 |
| Client ↔ Read API | HTTP/REST | JSON | 8081 |
| APIs ↔ Core API | gRPC | Protobuf | 50051 |
| Core API ↔ MongoDB | MongoDB Wire Protocol | BSON | 27017 |
| Core API ↔ Neo4j | Bolt Protocol | Cypher | 7687 |
| Core API ↔ PostgreSQL | PostgreSQL Wire Protocol | SQL | 5432 |
Network Architecture
Docker Network: ldf-network (bridge network)
All services run within the same Docker network:
- Container-based service discovery
- Internal communication via container names
- Health checks ensure proper startup sequencing
- Volume persistence for data storage
Exposed Ports:
8080- Ingestion API (external access)8081- Read API (external access)50051- Core API (can be internal only)27017- MongoDB (development access)7474/7687- Neo4j (development access)5432- PostgreSQL (development access)
Deployment
Containerization
The system leverages Docker and Docker Compose for containerization, running all services within a shared bridge network. This setup ensures consistent environments and manages the persistence of database storage through volumes.
Health Checks
Integrated health checks are configured for all services to ensure proper startup sequencing. The Core API waits for databases to be ready, while the Ingestion and Read APIs wait for the Core API, ensuring a stable initialization process.
Service Orchestration
Services use dependency management to start in the correct order: databases initialize first, followed by the Core API, and finally the Ingestion and Read APIs. A default Docker Compose profile runs all core services, while a separate 'cleanup' profile is available to trigger the database cleanup service.
Technology Stack
| Component | Technology | Language | Purpose |
|---|---|---|---|
| Ingestion API | Ballerina | Ballerina | REST API for mutations |
| Read API | Ballerina | Ballerina | REST API for queries |
| Core API | Go + gRPC | Go | Business logic orchestration |
| MongoDB | MongoDB 5.0+ | - | Metadata storage |
| Neo4j | Neo4j 5.x | - | Graph storage |
| PostgreSQL | PostgreSQL 14+ | - | Attribute storage |
| Protobuf | Protocol Buffers | - | Service communication |
| Docker | Docker + Compose | - | Containerization |
| Testing | Go test, Bal test, Python | Multiple | Unit & E2E tests |
Key Features
1. Polyglot Database Strategy
- Optimized Storage: Each database serves its best use case
- Data Separation: Clear boundaries between metadata, entities, and attributes
- Scalability: Independent scaling of each database
2. Time-Based Data Support
- Temporal Attributes: Track attribute values over time
- Temporal Relationships: Time-bound entity relationships
- Historical Queries: Query data at specific points in time (activeAt parameter)
3. Type Inference
- Automatic Detection: No manual type specification required
- Rich Type System: Supports primitives and special types
- Storage Optimization: Determines optimal storage based on data structure
4. Schema Evolution (Not Fully Supported)
- Dynamic Schemas: PostgreSQL tables created on-demand
- Attribute Flexibility: New attributes don't require migrations
- Kind-Based Organization: Attributes organized by entity kind
5. Graph Relationships
- Native Graph Storage: Neo4j for optimal relationship queries
- Bi-directional Support: Forward and reverse relationship traversal
- Relationship Properties: Rich metadata on relationships
6. Backup & Restore
- Polyglot Database Backup: Coordinated backups across all databases
- Version Management: GitHub-based version control
- One-Command Restore: Simple restoration from any version
7. API Contract-First
- OpenAPI Specifications: APIs defined before implementation
- Code Generation: Service scaffolding from contracts
- Documentation: Swagger UI for interactive API docs
Related Documentation
- How It Works - Detailed data flow documentation
- Data Types - Type inference system details
- Storage Types - Storage type inference details
- Backup Integration - Backup and restore guide
- Core API - Core API documentation
- Service APIs - Service APIs documentation